最近看到一个不错的MySQL讲解视频,讲的很细致也很基础。我自己学完数据库原理都很久了,MySQL索引 也都忘的差不多了,下面是自己整理的内容,主要从Hash、AVL、B-Tree等数据结构来分析MySQl的innoDB引擎的索引为什么使用B-Tree,以及如何正确的建立高效的索引。
1.什么是索引
- 索引是帮助MySQL高效获取数据的数据结构
- 在RDBM(关系型数据库),索引是存储在硬盘中的。
MySQL中的索引
- Hash索引: Adaptive Hash Index(自适应Hash索引,系统自动判断是否启用)
- BTree索引:也就是我们自己经常使用的索引对应的B+Tree数据结构。
2.相关数据结构
既然索引是一种数据结构,那么就不得不把和MySQL的索引(B+Tree)相关的数据结构经行对比。
Hash
Hash索引有一下特点:
- Hash索引是在内存中,会占用内存。
- 经给Hash函数建立索引,索引列存贮的有Hash值和数据地址指针。
- Hash索引查询数据较多时,生成对应Hash值需要一定时间。
- Hash索引是无序的,只适合等值查询,对于排序或者范围查找效率低。
- Hash碰撞较多时,一个索引里面对应多个地址指针,效率很低。
综合以上特点,MySQL的innoDB引擎是不让我们手动创建Hash索引的,目前只有memory这个引擎支持用户主动使用Hash索引。
BST
二叉搜索树(BST)定义:一个节点最多分裂出来两个节点,大的放右边,小的放左边。
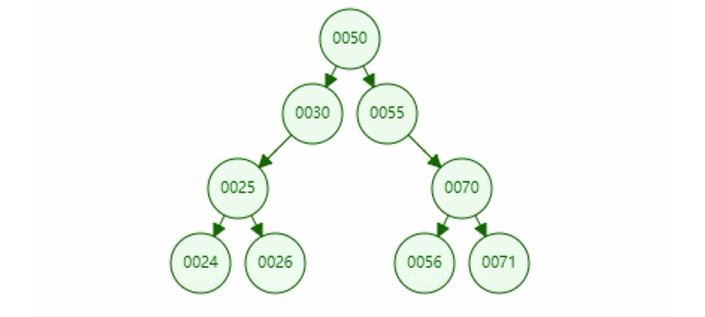
这种树结构查询效率明显比普通二叉树要快,但是如果数据是下面的情况:
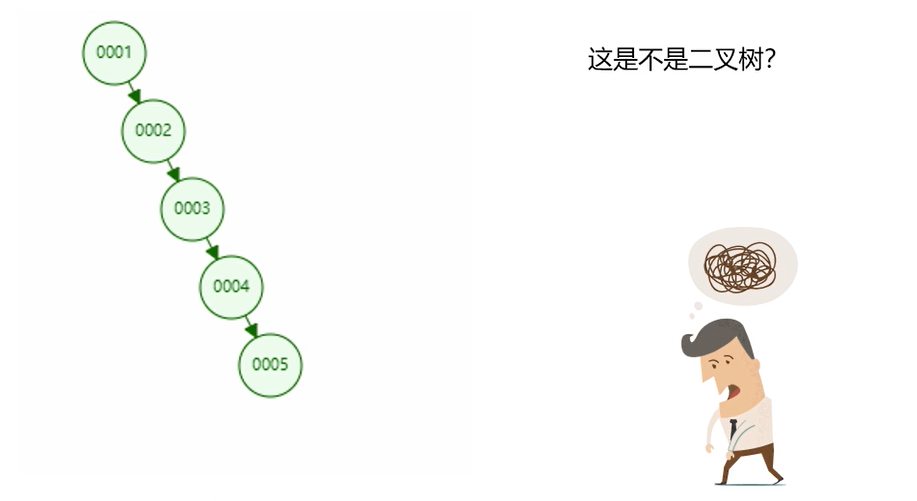
当我们查询5的时候,我们要查询5次。你会发现和没使用任何数据结构是一样的。所以这种数据结构还是有一定问题的。
AVL
后来又有了新的一种树型数据结构,平衡二叉搜索树(AVL)。AVL:要求左子树和右子树必须都是平衡二叉树,并且深度差不能超过1。如果新插入的元素不能满足这种特性,必须通过左旋或者右旋操作来维持这一特性。
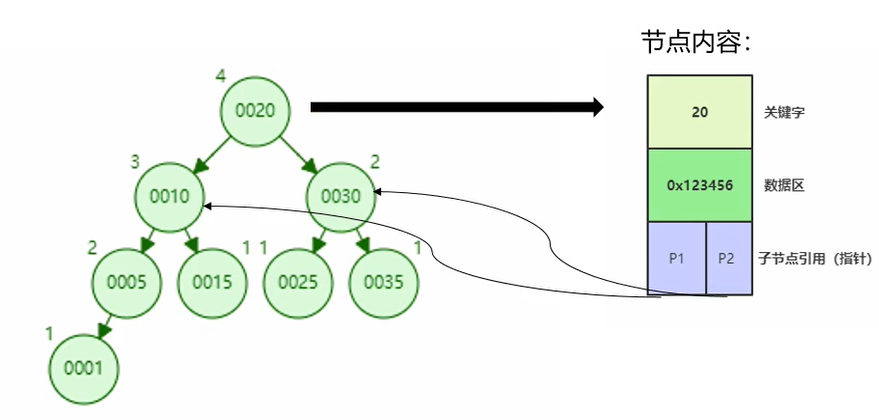
可以发现,我们查询一个数据的次数和树的度有关,树的高度越低,查询一个数据的次数就越少,当我们的数据很多50w、1000w,树的高度可想而知。这就增加了IO次数,遍历了很多节点但是只查询了一个数据,造成了很大的IO浪费。
B-Tree
B-Tree (多路搜索树/多叉平衡查找树) ,B-Tree相对于AVL的特点:
- 它的节点关键字,由一个变成了多个。
- 原来只能是二叉树,现在可以是多叉树。
- B-Tree要求绝对的平衡,子树不允许存在高度差。
- 节点数据对应子节点值一个左闭右开的范围,详情见下图。
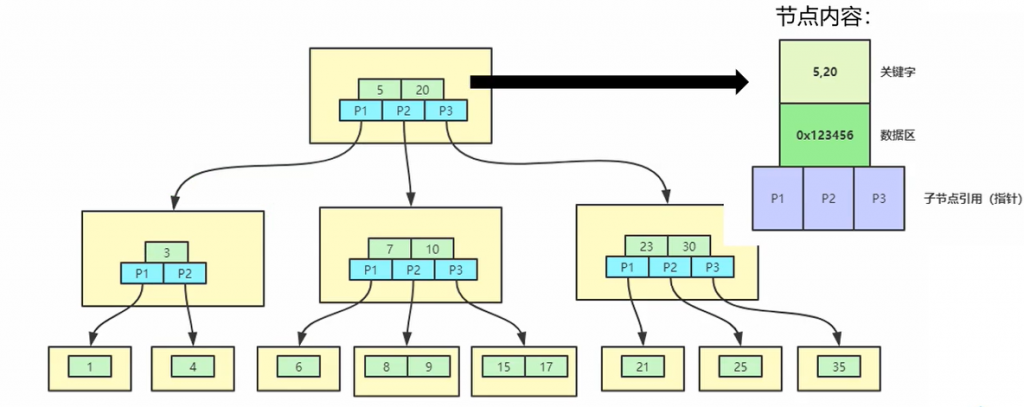
使用B-Tree明显可以降低树的高度,可以减少我们遍历的次数。
B+Tree
可能大家觉得B-Tree已经很优秀了,但是为什么MySQl索引的数据结构还是使用的B+Tree呢,B+Tree在B-Tree的基础上又进行了改进。它相对于B-Tree又有以下新的特点:
- 节点数:路数=1:1
- 非叶子节点不再有数据区。
- 所有数据区都移到叶子节点。
- 叶子节点可以看作是一个有序的双向链表。
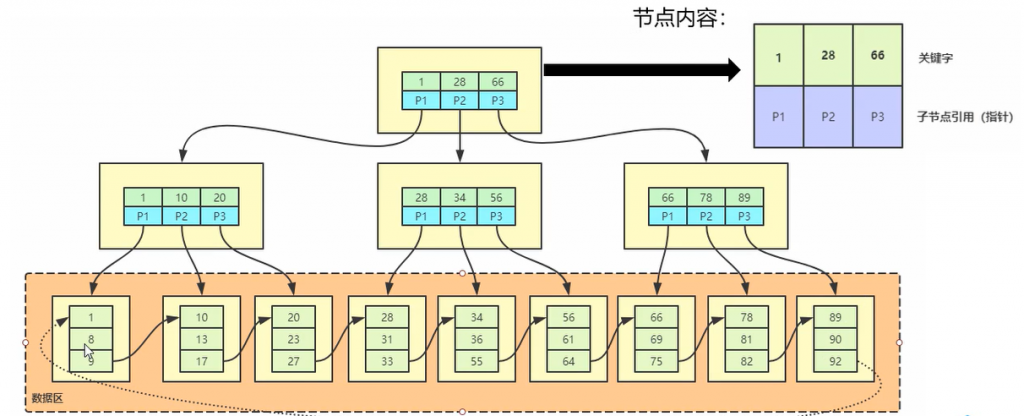
相对于B-Tree,B+Tree有下面几个优点:
- 基于索引的扫表、扫库更强。
- 基于索引的排序更强。
- 对于数据的划分更加清晰。
3.MySQL的索引
MySQL有两个比较常见的引擎:
- Myisam引擎
- InnoDB引擎
Myisam
主键索引
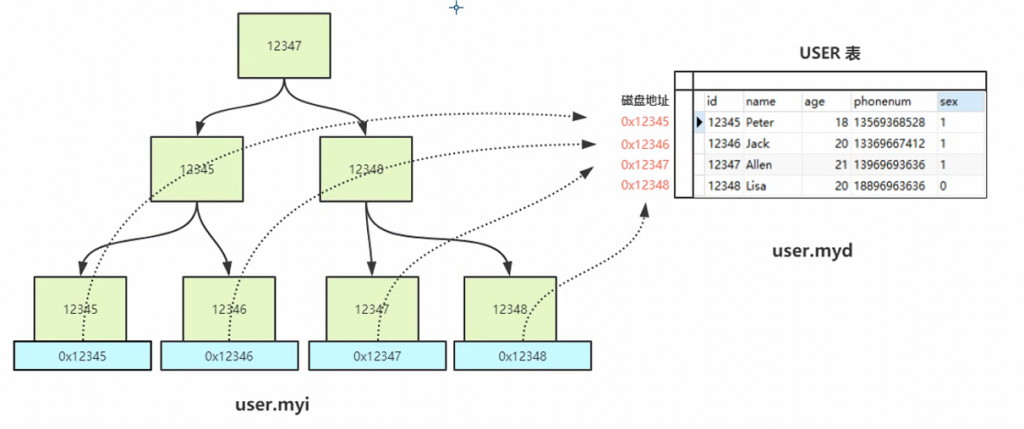
myisam建立主键索引时,会创建两个文件.myi(索引结构)、.myd(数据),通过查询.myi文件中的叶子节点拿到行地址,再去.myd中找到对应的数据。
非主键索引
对于非主键索引,也是需要先到.myi文件中获得对应的地址,然后去.myd文件中获取对应的数据。
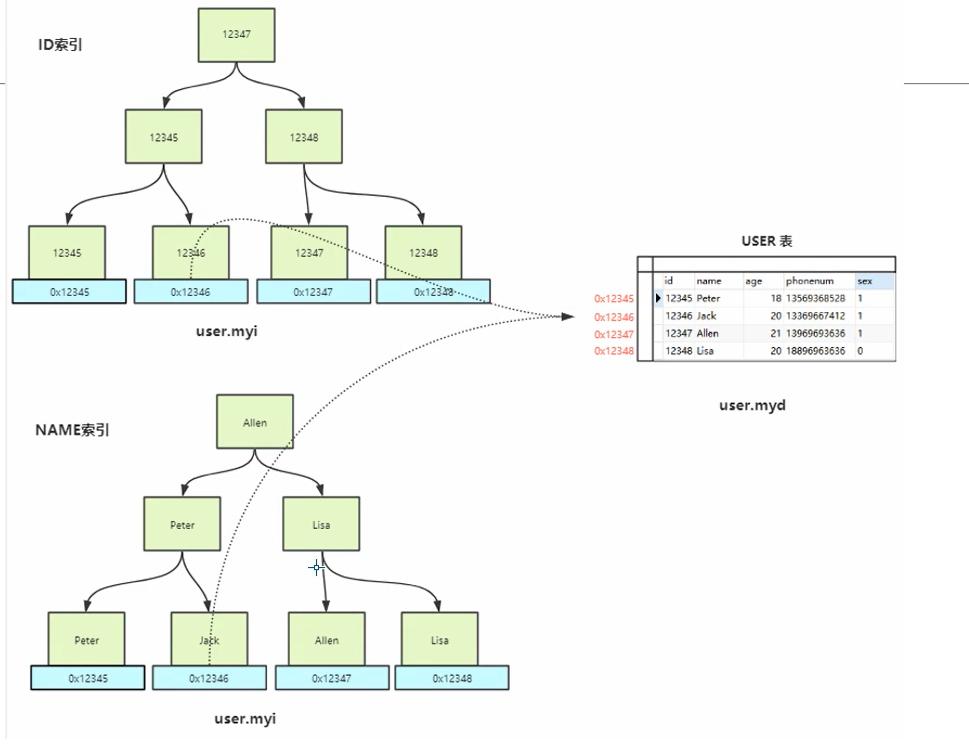
所以对myisam引擎来说,无论是主键索引还是非主键索引,索引中的叶子节点都只存贮地址信息,拿到地址后还是要去.myd文件查找真正的数据。
InnoDB
主键索引
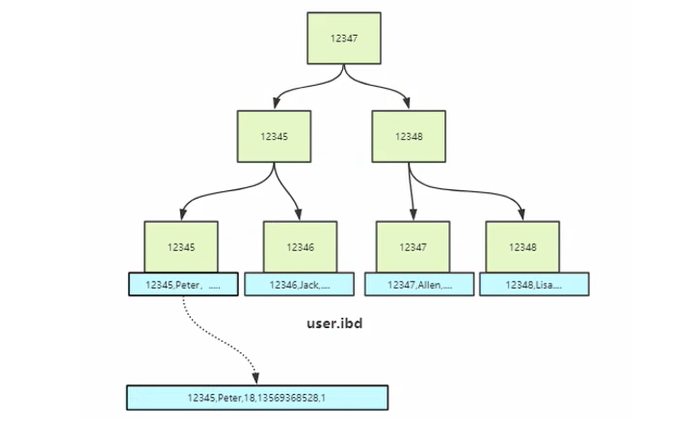
下面是InnoDB的主键索引(在InnoDB只有主键索引是聚集索引,因为只有主键索引保存的是真正的行记录),在主键索引的的叶子节点不再是存贮地址而是对应的行记录,当我们查询到对应信息就可以直接返回对应的信息。
非主键索引
在InnoDB中,它的非主键索引叶子节点并没有存贮对应的行记录,非主键索引的叶子节点保存的是当前索引列的值和主键的值。
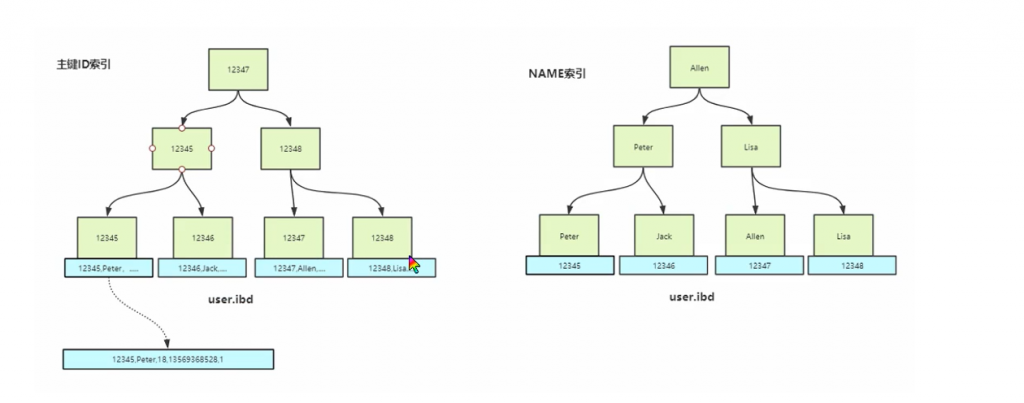
列的离散性
当我们建立索引时,选这建立的字段离散性尽量要高,即对应列的值重复度要低
单例索引
#节点关键字 name
create index user(name);联合索引
create index user(name,age,phoneNum)上面建立的联合索引实际上会产生三个索引:
- name
- name age
- name age phoneNum
下面三条sql,对应分析索引使用情况
#SQL查询1
select * from user where name='Yremp' and age=20 and phoneNum=1809161
#SQL查询2
select * from user where age=20 and phoneNum=1809161
#SQL查询3
select * from user where name='Yremp' and phoneNum=1809161
#SQL查询
select * from user where name='Yremp' and age>12 and phoneNum=1809161- 当我们使用 Yremp 20 1809161 进行查询的时候,会依次匹配索引name age phoneNum,三个索引字段都被使用到了
- 当我们使用 20 1809161 进行查询的时候,B+Tree没办法找到name属性匹配,这样的查询所有的索引是无效的。
- 当我们使用 name phoneNum进行匹配时,Yremp是可以通过索引中name对应的进行匹配数据,但是由于age的缺失,后面它只能通过phoneNum进行等值查询,也就是说只用到了name索引。
- 对于第四条sql,在a>12之后的,phoneNum对应的索引是无效的,范围之后索引全部失效。
覆盖索引
通过索引项的信息可以直接返回所查询的列,则该索弓|称为查询SQL的覆盖索引。尽量使用覆盖索引,他能加快查询速度。具体的可以查看下面的例子:
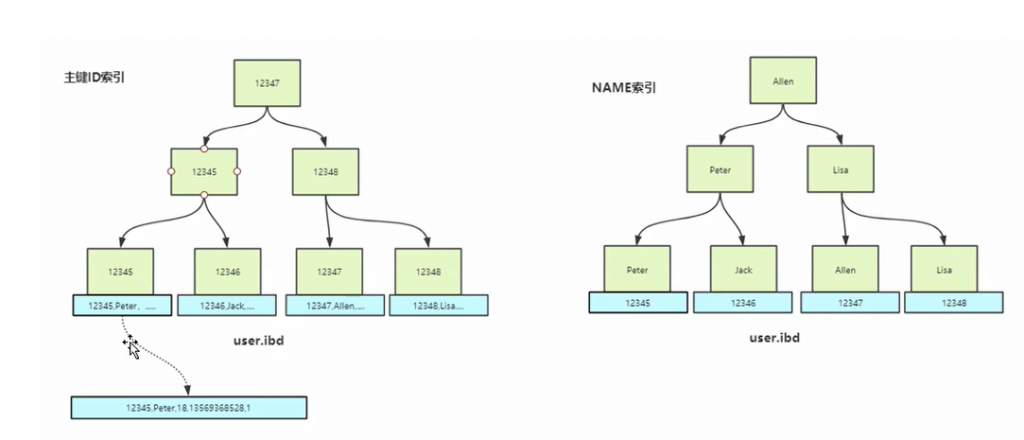
在上面的name索引中,叶子节点保存了name的值以及主键ID的信息。下面有两条针对上面信息的SQL:
#SQL 1
select * from user where name='Peter'
#SQL 2
select id,name from user where name='Peter'- SQL 1:当我们在name索引树中,当我们找到了neme=Peter的节点之后,还需要通过主键去主键ID索引中查询对应的全部信息(*)。
- SQL 2:当我们在name索引树种找到了name=Peter的叶子节点,发现id也在里面,这时候就可以直接返回结果,不需要像SQL 1一样还要去主键ID索引中再去查找一次。
注意:上面SQL 1 在查询了一次name索引之后又去主键ID索引中查询一次的就称作:回表。SQL 2也就是覆盖索引。很明显回表查询效率是很低的,所以尽量使用覆盖索引。
三星索引
- where后面匹配的索索引关键字列越多越好,扫描的数据越精确,越少越好。通过索引筛选出的数据越少越好。(离散性)
- 避免再次排序(索引字段天然有序,避免非索引字段二次排序)。
- 尽可能应用覆盖索引。减少回表操作。
标签云
ajax AOP Bootstrap cdn Chevereto CSS Docker Editormd GC Github Hexo IDEA JavaScript jsDeliver JS樱花特效 JVM Linux Live2D markdown Maven MyBatis MyBatis-plus MySQL Navicat Oracle Pictures QQ Sakura SEO Spring Boot Spring Cloud Spring Cloud Alibaba SpringMVC Thymeleaf Vue Web WebSocket Wechat Social WordPress Yoast SEO 代理 分页 图床 小幸运 通信原理

Comments | NOTHING